
Tư Vấn Big Data
VietOCR.NET Phần mềm nhận dạng hình ảnh và sử lý văn bản trên hình ảnh và file pdf
VietOCR, hiện có trong Java and .NET executable, là một GUI frontend cho Tesseract OCR engine. Cả hai phiên bản đều có giao diện tương tự và có cùng khả năng nhận diện ký tự từ các loại dạng ảnh phổ thông. Chương trình còn có khả năng vận hành như một ứng dụng console, thi hành lệnh từ command line.
Batch processing cũng được hỗ trợ. Chương trình theo dõi một watch folder cho các tập tin ảnh mới, tự động xử lý chúng qua OCR engine, và xuất kết quả nhận dạng ra một output folder.
Language data cho Việt ngữ và Anh ngữ đã được gói kèm với chương trình. Data cho các ngôn ngữ khác có thể hạ tải từ Tesseract website và cần đặt vào tessdata folder. Lưu ý rằng language data files cho Tesseract 2.0x và 3.0 có định dạng khác nhau và không hoán đổi cho nhau được, vì vậy hãy hạ tải files tương thích với phiên bản Tesseract bạn có (2.0x, 3.0).
Cài đặt
1. Phiên bản chạy trên java ( có ý nghĩa tham khảo, chưa thử thực tế ^-^ )
Phiên bản Java đòi hỏi Java Runtime Environment, 6.0 hoặc mới hơn. Cho Linux, bạn có thể cài đặt JRE từ Libraries (multiverse) repository qua Synaptic Package Manager hoặc từ terminal, như sau:
sudo apt-get install sun-java6-jre sun-java6-plugin
Tesseract và language data packages nằm trong Graphics (universe) repository. Chúng có thể được cài qua Synaptic hoặc từ lệnh sau:
sudo apt-get install tesseract-ocr tesseract-ocr-vie
Files sẽ được đặt trong /usr/bin và /usr/share/tesseract-ocr/tessdata, trong thứ tự đó.
Mặt khác, nếu Tesseract được xây dựng và cài từ mã nguồn, chúng sẽ được đặt trong /usr/local/bin và /usr/local/share/tessdata. Bạn cần chỉ định directory của Tesseract executable từ Settings menu của VietOCR. VietOCR được thiết kế để nhận biết các tập tin language data ở những địa điểm đó; tuy nhiên, trong trường hợp tessdata được để vào trong một directory khác với những directory đã đề cập, bạn sẽ cần đặt biến môi trường TESSDATA_PREFIX environment variable, ví dụ:
export TESSDATA_PREFIX=/usr/local/share/
(hoặc tương đương) trong .profile của bạn hoặc setenv để đặt biến môi trường. Hãy chú ý rằng đường dẫn tới directory phải kết với ký tự /.
2. Phiên bản chạy trên window
Phiên bản .NET cần Microsoft .NET Framework 2.0 Redistributable. Nếu bạn gặp FileLoadException với message "Could not load file or assembly 'tessnet2, Version=2.0.4.0, Culture=neutral, PublicKeyToken=null' or one of its dependencies. This application has failed to start because the application configuration is incorrect. Reinstalling the application may fix this problem. (Exception from HRESULT: 0x800736B1)" trong khi đang chạy VietOCR.NET, xin hãy cài đặt Microsoft Visual C++ 2008 SP1 Runtime (x86, x64).
Tiến hành cài đặt như các phần mềm khác.
Lưu ý: Sau khi cài đặt xong thì phải copy file thư viện: “gsdll32.dll” vào thư mục cài đặt.
II. Sử dụng phần mềm
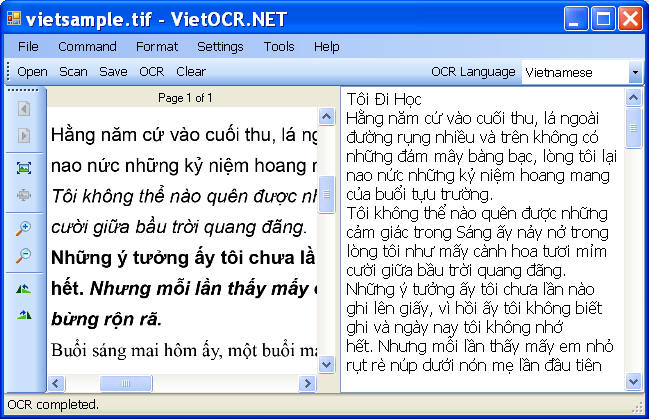
- Chạy phần mềm => chọn ngôn ngữ cho bản dịch tại: “OCL language” => Mở File cần xử lý ra ( Lưu ý đối với các file .pdf lớn thì phải copy ra một thư mục riêng trước khi mở vì chương trình sẽ tự động cắt nhỏ các file lớn thành hình ảnh ) => Sau khi mở được file, ta chọn nút: “ OCR” để xử lý văn bản.
Hình 1: VietOCR.NET WinForm GUI
Có thể chọn xử lý từng phần của văn bản bằng cách kéo chuột trên vùng muốn xử lý và chọn nút: “OCR” như hình 02

Hình 2: VietOCR Swing GUI
Lưu ý: có thể chọn giao diện tiếng Việt trong phần Settings như hình 03

Hình 03. Chọn giao diện tiếng Việt
Tác vụ OCR
Bộ Vietnamese language data được tạo cho các font Times New Roman, Arial, Verdana, và Courier New. Do đó, việc nhận dạng sẽ có kết quả cao hơn cho các ảnh có font glyphs tương tự. OCR ảnh có font glyph trông khác các font hỗ trợ thông thường sẽ đòi hỏi tập huấn Tesseract để tạo một bộ language data khác cụ thể cho những mặt chữ đó.
Cập nhật: Thêm language data đã được tạo cho các kiểu font cũ Việt Nam, VNI và TCVN3 (ABC). (Đọc phương cách cài.)
Hình ảnh muốn được OCR cần quét ở độ phân giải từ 200 DPI (dot per inch) trở lên tới 400 trong trắng đen hoặc grayscale. Quét ảnh với độ phân giải cao hơn nữa chưa hẳn sẽ tăng sự chính xác của kết quả nhận dạng. Hiện tại, mức chính xác có thể lên trên 97% cho Tiếng Việt (ảnh chuẩn), và phiên bản tới của Tesseract có thể nâng cao độ nhận dạng hơn nữa. Dầu vậy, độ chính xác thực thụ vẫn còn tùy thuộc rất lớn vào phẩm chất của ảnh quét.
Thông số tiêu biểu cho quét ảnh là 300 DPI và 1 bpp (bit per pixel) trắng đen hoặc 8 bpp grayscale dạng uncompressed TIFF hay PNG. PNG nhỏ gọn hơn những dạng ảnh khác mà vẫn giữ được chất lượng cao nhờ sử dụng thuật toán lossless data compression; TIFF có lợi điểm ở khả năng chứa nhiều trang ảnh (multi-page) trong một file.
Ngoài thuật toán hậu xử lý xây trong chương trình, bạn có thể thêm cách thức thay thế từ ngữ đặc riêng của bạn qua một tập tin text có tên x.DangAmbigs.txt, mà x là ISO639-3 language code. File này, được mã hóa trong UTF-8, chứa các cặp giáTrịCũ=giáTrịMới phân cách bởi dấu bằng.
Vài công cụ gắn liền được cung cấp để nối nhiều file ảnh hoặc PDF vào một file đơn để thuận tiện cho các tác vụ OCR, hoặc tách một file PDF thành nhiều file nhỏ hơn nếu nó quá lớn, điều mà có thể gây ra biệt lệ cạn bộ nhớ. Chép ảnh (paste image) từ clipboard đã được hỗ trợ.
Lưu ý: Ảnh screenshot hay screen capture điển hình chỉ có 96 DPI, một độ phân giải không đủ cho những đòi hỏi của OCR.
Hậu xử lý
Các lỗi nhận diện ký tự Việt có thể phân làm ba loại. Nhiều lỗi thường bị bởi do lẫn lộn chữ hoa và chữ thường (upper and lower) — ví dụ: hOa, nhắC — có thể dễ dàng sửa chữa sử dụng các chương trình Unicode text editor. Lỗi do sự xử lý không chính xác, gây ra các lỗi như thiếu sót dấu, lầm với ký tự có hình dáng tương tự, v.v… — huu – hưu, mang – marg, h0a – hoa, la – 1a, uhìu - nhìn. Đa số các lỗi này cũng có thể dễ dàng sửa chữa dùng các phần mềm duyệt chính tả. Hàm Hậu xử lý của VietOCR có thể sửa được nhiều lỗi nêu trên.
Loại lỗi cuối cùng là khó phát hiện nhất bởi chúng liên quan đến ngữ nghĩa, semantics, có nghĩa là những chữ đánh vần đúng (tức là mục từ có trong tự điển), nhưng sai nghĩa trong ngữ cảnh (context) — ví dụ: tinh – tình, vân – vấn. Những lỗi này cần phải có người đọc duyệt lại và sửa theo bản gốc trong hình.
Quy trình biên tập sau đây với chương trình VietPad text editor được đề ý:
- Gom dòng. Các hàng chữ (line) cần được gom lại theo từng đoạn (paragraph), bởi khi được OCR, mỗi hàng chữ trở thành đoạn 1-hàng tách riêng. Dùng tính năng Nối dòng trong menu Định dạng. Lưu ý rằng tác vụ này có thể không cần cho thi thơ.
- Cũng trong menu Định dạng, bấm Đổi ngữ cách và chọn Chữ hoa đầu câu để sửa gần như tất cả các lỗi chữ hoa-thường. Hãy dò tìm và sửa các lỗi hoa-thường còn sót.
- Sửa lỗi chính tả bằng tính năng Dò chính tả dưới menu Công cụ.
Qua các bước trên, hầu hết các lỗi thông thường sẽ được loại trừ. Những lỗi ngữ nghĩa semantic còn sót lại ít, nhưng đòi hỏi người duyệt đọc dò lại toàn bộ văn bản để được giống y như văn bản gốc quét, và toàn thiện nếu muốn.
Giới hạn
Tesseract 2.0x không hỗ trợ dàn trang, cho nên chỉ có thể nhận diện văn bản có một cột text. Tesseract 3.0 đã tích hợp tính phân tích dàn trang, hỗ trợ nhận dạng các văn bản có nhiều cột.
Tham khảo thêm tại link sau:
http://vietocr.sourceforge.net/usage_vi.html
Links down phần mềm:
http://sourceforge.net/projects/vietocr/
(st)
DVMS chuyên:
- Tư vấn, xây dựng, chuyển giao công nghệ Blockchain, mạng xã hội,...
- Tư vấn ứng dụng cho smartphone và máy tính bảng, tư vấn ứng dụng vận tải thông minh, thực tế ảo, game mobile,...
- Tư vấn các hệ thống theo mô hình kinh tế chia sẻ như Uber, Grab, ứng dụng giúp việc,...
- Xây dựng các giải pháp quản lý vận tải, quản lý xe công vụ, quản lý xe doanh nghiệp, phần mềm và ứng dụng logistics, kho vận, vé xe điện tử,...
- Tư vấn và xây dựng mạng xã hội, tư vấn giải pháp CNTT cho doanh nghiệp, startup,...
Vì sao chọn DVMS?
- DVMS nắm vững nhiều công nghệ phần mềm, mạng và viễn thông. Như Payment gateway, SMS gateway, GIS, VOIP, iOS, Android, Blackberry, Windows Phone, cloud computing,…
- DVMS có kinh nghiệm triển khai các hệ thống trên các nền tảng điện toán đám mây nổi tiếng như Google, Amazon, Microsoft,…
- DVMS có kinh nghiệm thực tế tư vấn, xây dựng, triển khai, chuyển giao, gia công các giải pháp phần mềm cho khách hàng Việt Nam, USA, Singapore, Germany, France, các tập đoàn của nước ngoài tại Việt Nam,…
Quý khách xem Hồ sơ năng lực của DVMS tại đây >>
Quý khách gửi yêu cầu tư vấn và báo giá tại đây >>








