
Xây dựng hệ thống tự động chấm bài thi trắc nghiệm với OpenCV và Deep Learning
Chấm phiếu điền trắc nghiệm bằng OpenCV và Deep Learning
Phiếu trắc nghiệm không phải lúc nào cũng có dạng chuẩn..?
Thi trắc nghiệm đã và đang trở thành xu hướng bởi tính khách quan (Không phụ thuộc người chấm) của nó. Tuy nhiên, việc chấm một số lượng lớn bài thi trắc nghiệm đôi khi lại là một công việc không hề "hứng thú " chút nào bởi đơn giản không phải ở đâu chúng ta cũng có được những máy chấm trắc nghiệm tự động để khiến cho công việc này trở nên nhanh chóng.Thông thường, một phiếu điền trắc nghiệm sẽ có dạng như sau:
Mục tiêu
Có lẽ với tờ phiếu trắc nghiệm như trên, rất nhiều người sẽ chọn giải pháp là ngồi so đáp án và .. chấm thủ công bằng tay, tuy nhiên khi số lượng là không ít, thì đây có lẽ là phương án tồi nhất . Vậy ngày hôm nay, mình muốn viết bài này với mong muốn đưa ra 1 giải pháp giúp các bạn có thể giải quyết được vấn đề nêu trên bằng cách thử xây dựng một mô hình Deep Learning kết hợp với các phương pháp xác định đối tượng rất đơn giản.
Phương pháp tiếp cận bài toán
Đối với nhưng bài toán thực tế dạng này (Nhận diện biển báo giao thông cho xe không người lái, nhận diện chướng ngại vật, xác định vật thể, ..) bài toán của chúng ta sẽ được chia làm 2 bài toán nhỏ hơn:
- Bài toán xác định (Detection): Thực hiện các phương pháp xử lý ảnh (Resize, Threshold, ..) để có thể xác định được các vị trí của vật thể cần tìm trong ảnh/ video nhằm làm đầu vào cho bài toán Nhận dạng tiếp theo.
- Bài toán nhận dạng (Classification): Sử dụng các mô hình deep learning hoặc SVM để xác định/ nhận dạng các vật thể vừa xác định được nhằm đưa ra được kết quả.
Trong bài viết lần này, chúng ta sẽ sử dụng thư viện OpenCV để thực hiện bài toán đầu tiên, và sử dụng tflearn (1 thư viện xây dựng trên tensorflow) để xây dựng mạng deeplearning cho bài toán thứ hai.
Xây dựng mô hình thực tế
Sử dụng OpenCV cho bài toán Object Detection
Mục tiêu của phần này như đã nói ở trên, chúng ta sẽ xử lý ảnh qua các phương pháp thông thường để có thể xác định được chính xác vị trí của các đáp án trắc nghiệm mà thí sinh đã ghi lại.
Với bức ảnh như ở đầu bài viết, chúng ta có thể dễ thấy, các đáp án nằm gọn trong 1 ô của 1 bảng điền, mỗi dòng sẽ có 2 ô đặt cách khá đều nhau (kích thước cố định) và có 19 dòng kích thước như nhau ở trong bảng.
Nói đến đây, chắc hẳn chúng ta đã có phương án làm bài toán trở nên đơn giản hơn rất nhiều. Từ việc xác định vị trí của 36 ô đáp án, giờ chúng ta chỉ cần cố gắng xác định được tọa độ chính xác của bảng điền trong ảnh, sau đó chia tỷ lệ ra làm 19 lần theo chiều dọc là sẽ lấy được dòng và các đáp án! Một bài toán đơn giản hơn rất nhiều!
Và với bài toán xác định ví trí bảng như thế này, việc tìm ra các đường kẻ thẳng và ngang ở trong ảnh được cho là 1 phương án rất hiệu quả.
Hãy bắt đầu với việc đưa ảnh về binary bằng cách sử dụng hàm threshold của openCV
img = cv2.imread("./multiple_choice.jpg", 0)
blur = cv2.GaussianBlur(img,(5,5),0)
thresh = cv2.adaptiveThreshold(blur,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV,11,2)
Ở đây, trước khi đưa vào hàm binary, mình có sử dụng thêm 1 hàm làm mờ, việc này giúp ảnh của chúng ta giảm được rất nhiều nhiễu, và khiến cho ảnh qua threshold được mịn hơn rất nhiều. Các hằng số mình truyền vào ở đây có ý nghĩa là làm cho ảnh đầu ra của mình đưa về dạng đen-trắng (nền đen, chữ trắng). Và đây là kết quả thu được

Đây là ảnh sẽ giúp cho những đoạn xử lý sau của chúng ta được đơn giản và độ chính xác cao hơn rất nhiều.
Giờ sẽ là lúc để xác định vị trí của các đường ngang và đường dọc trong ảnh
horizal = thresh
vertical = thresh
scale_height = 20 #Scale này để càng cao thì số dòng dọc xác định sẽ càng nhiều
scale_long = 15
long = int(img.shape[1]/scale_long)
height = int(img.shape[0]/scale_height)
horizalStructure = cv2.getStructuringElement(cv2.MORPH_RECT, (long, 1))
horizal = cv2.erode(horizal, horizalStructure, (-1, -1))
horizal = cv2.dilate(horizal, horizalStructure, (-1, -1))
verticalStructure = cv2.getStructuringElement(cv2.MORPH_RECT, (1, height))
vertical = cv2.erode(vertical, verticalStructure, (-1, -1))
vertical = cv2.dilate(vertical, verticalStructure, (-1, -1))
mask = vertical + horizal
Cùng nhìn qua một chút, ban đầu, chúng ta sẽ lấy ra 2 ảnh từ ảnh thresh gốc, sau đó, xác định cấu trúc của các ảnh với hàm getStructuringElement của OpenCV trước khi đưa nó vào 2 bước erode(làm mỏng) và dilate(làm dày). Ở đây, với cấu trúc lấy được, sau khi đưa qua bước erode, ảnh của chúng ta sẽ chỉ còn lại các đường thẳng hoặc ngang, bước dilate giúp chúng ta làm rõ hơn các đường này. Và đây là kết quả:

Khá thành công! Giờ là lúc chúng ta sẽ xác định ra vị trí của bảng thông qua bức hình trên. Để làm được điều này, chúng ta cần sử dụng hàm findCountours của OpenCV
_, contours, hierarchy = cv2.findContours(mask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
max = -1
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
if cv2.contourArea(cnt) > max:
x_max, y_max, w_max, h_max = x, y, w, h
max = cv2.contourArea(cnt)
Hàm findCountours sẽ giúp chúng ta lấy vị trí của các vật thể kín trong 1 bức hình. Ở đây, nó có thể sẽ lấy ra được rất nhiều vị trí của các vật thể (Mỗi dòng là 1 vật thể, mỗi ô là 1 vật thể). Tuy nhiên chúng ta sẽ chỉ cần lấy vật thể lớn nhất đó chính là bảng điền! OKKK, thử in kết quả vừa xác định được ra xem nào!
table = img[y_max:y_max+h_max, x_max:x_max+w_max]
Gần như hoàn hảo phải không) Vậy là bài toán 1 của chúng ta đã được giải quyết ...GẦN xong. OpenCV giúp chúng ta cắt được bảng điền ra trong 1 ảnh với những bước xử lý rất đơn giản!
Cuối cùng ở bước này, chúng ta sẽ chia bảng ra theo các tỷ lệ nhằm cắt được các ô đáp án một cách gần chính xác nhất, sau đó, mỗi ô đáp án cần, chúng ta sẽ lại sử dụng hàm findCountours để xác định ra ký tự được viết ở ô đó.
cropped_thresh_img = []
cropped_origin_img = []
countours_img = []
NUM_ROWS = 19
START_ROW = 1
for i in range(START_ROW, NUM_ROWS):
thresh1 = thresh[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(w_max/6):x_max +round(w_max/2)]
_, contours_thresh1, hierarchy_thresh1 = cv2.findContours(thresh1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
origin1 = img[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(w_max/6):x_max +round(w_max/2)]
cropped_thresh_img.append(thresh1)
cropped_origin_img.append(origin1)
countours_img.append(contours_thresh1)
for i in range(START_ROW, NUM_ROWS):
thresh1 = thresh[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(2*w_max/3):x_max +round(w_max)]
_, contours_thresh1, hierarchy_thresh1 = cv2.findContours(thresh1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
origin1 = img[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(2*w_max/3):x_max +round(w_max)]
cropped_thresh_img.append(thresh1)
cropped_origin_img.append(origin1)
countours_img.append(contours_thresh1)
Trong đoạn code trên, ta nhận thấy bảng có 19 hàng, vậy nên chiều dọc sẽ được chia ra làm 19 phần, ta sẽ thu được 1/19 chiều dọc của bức ảnh chính là 1 dòng. Ở mỗi dòng, ta có thể ước lượng, ô câu hỏi có kích thước bằng khoảng 1/2 ô đáp án, vậy nên ta sẽ chia chiều ngang ra làm 6 phần. Áp dụng findCountours chỉ cho những ô đáp án ta thu được toàn bộ vật thể nhận ra ở trong các ô đáp án (Dữ liệu được ghi vào mảng nên sẽ đảm bảo việc đúng thứ tự)
Và giờ thêm một vài điều kiện nhằm đảm bảo tính chính xác của đầu ra ta thu được các đáp án ghi lại một cách tuyệt đối.
for i, countour_img in enumerate(countours_img):
for cnt in countour_img:
if cv2.contourArea(cnt) > 30:
x,y,w,h = cv2.boundingRect(cnt)
if x > cropped_origin_img[i].shape[1]*0.1 and x < cropped_origin_img[i].shape[1]*0.9:
answer = cropped_origin_img[i][y:y+h, x:x+w]
answer = cv2.threshold(answer, 160, 255, cv2.THRESH_BINARY_INV)[1]
Với điều kiện này, contours sẽ chỉ được TÍNH nếu có kích thước lớn hơn 30 (Nhằm loại bỏ các vật thể NHIỄU) và với các countours tìm được, để không lấy phải 2 viền ô, ta sẽ chỉ khoanh vùng vào khoảng giữa của ô đáp án (vị trí >0.1*độ dài ô hoặc <0.9 *độ dài ô). Kết quả thu được như sau:

Và đây cũng chính là ảnh đầu vào mà chúng ta sẽ đưa vào mô hình để có thể thực hiện bài toán tiếp theo. Với ảnh các đáp án đã thu được ở trên, chúng ta có thể lưu lại vào mảng kết quả để tiện sử dụng sau này.
Sử dụng tflearn cho bài toán Classification
Mục tiêu của phần này chính ra từ những ảnh trên, xác định ra kết quả A, B, C, D tương ứng với từng ảnh nhằm lưu lại và so sánh với đáp án chính xác sau này.
Với bài toán này, có rất nhiều các model có sẵn trên mạng nhằm phục vụ cho việc classification, ở đây mình chỉ thực hiện việc xây dựng lại đồ thị bằng tflearn, sau đó load lại weight từ model có sẵn nhằm tiết kiệm thời gian training. Đồ thị có dạng như sau:
network = input_data(shape=[None, IMG_SIZE, IMG_SIZE, 1])
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 1024, activation='relu')
network = dropout(network, 0.8)
network = fully_connected(network, N_CLASSES, activation='softmax')
network = regression(network)
model = tflearn.DNN(network)
model.load("./model/letter.tflearn")
Hoàn toàn dễ hiểu và ngắn gọn. Nếu muốn tìm hiểu sâu hơn về cách thức hoạt động, cách training model nêu trên các bạn có thể tìm hiểu ở bài viết tại phần mở đầu
Và giờ đây, cho toàn bộ ảnh thu được từ các đáp án trên đi qua model, chúng ta sẽ thu được kết quả như mong muốn.
Với những ô không tìm thấy vật thể, đó chính là những ô không được ghi đáp án, ta sẽ đánh dấu X. Với những ô mà ta xác định được 2 vật thể trở lên, tạm thời chúng ta sẽ đánh O - không chắc chắn. Còn lại sẽ được đánh dấu đúng như bình thường.
...
res.append(np.argmax(model.predict(answer), axis=-1))
letter = ['A', 'B', 'C', 'D']
result = []
for r in res:
if len(r) == 0:
result.append("X")
elif len(r) > 1:
result.append("O")
else:
result.append(letter[int(r[0])])
print(result)
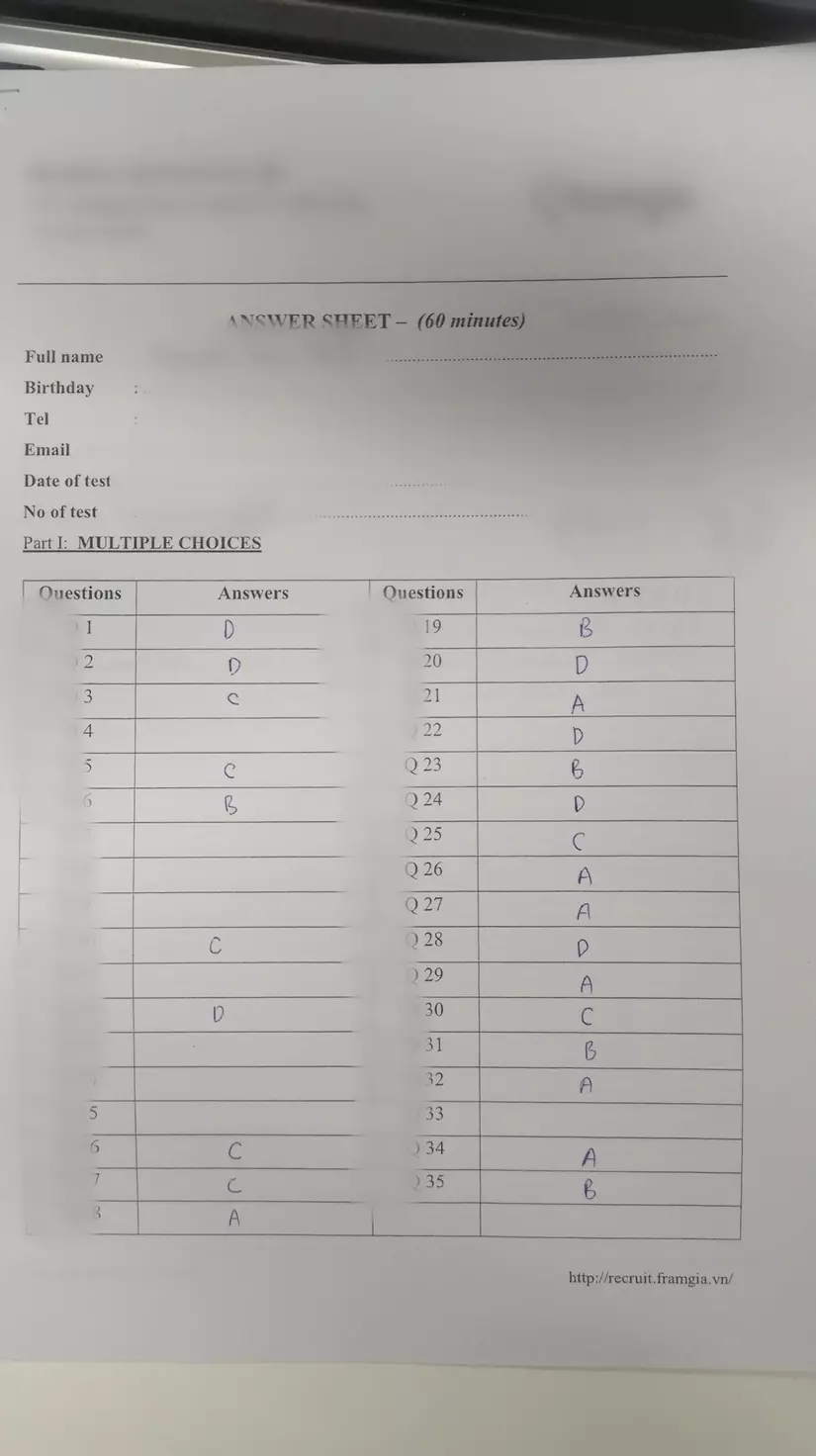
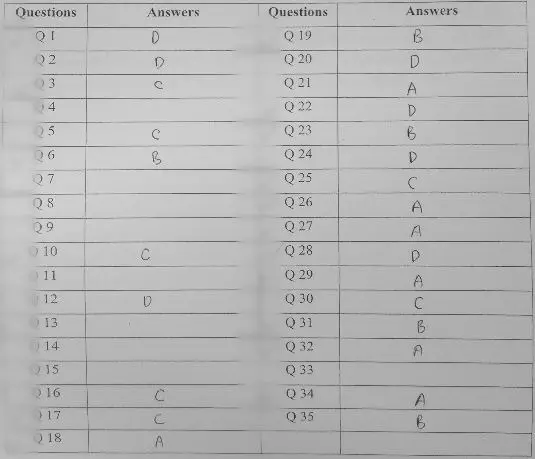
#Result: ['D', 'D', 'C', 'X', 'C', 'B', 'X', 'X', 'X', 'C', 'X', 'D', 'X', 'X', 'X', 'C', 'C', 'A', 'B', 'D', 'A', 'D', 'B', 'D', 'C', 'A', 'A', 'D', 'A', 'C', 'B', 'A', 'X', 'A', 'B', 'X']
Result: ['D', 'D', 'C', 'X', 'C', 'B', 'X', 'X', 'X', 'C', 'X', 'D', 'X', 'X', 'X', 'C', 'C', 'A', 'B', 'D', 'A', 'D', 'B', 'D', 'C', 'A', 'A', 'D', 'A', 'C', 'B', 'A', 'X', 'A', 'B', 'X']
Kết quả chính xác 100% so với bức ảnh trên! Và giờ mọi công đoạn so đáp án, thống kê hay lưu trữ số hóa ở sau đây đều có thể được thực hiện chỉ trong một vài câu lệnh đơn giản! Quá tuyệt vời phải không nào!
Các ngoại lệ
Với các bài toán thực tế mà ảnh đầu vào của chúng ta không được quy chuẩn như thế này, việc chọn các tham số cho các hàm của OpenCV là vô cùng quan trọng. Người viết khuyến cáo các bạn hãy dành thời gian để thử thật nhiều để tìm ra được các tham số phù hợp nhất cho bài toán của riêng mình. Chúc các bạn thành công!
Xây dựng hệ thống tự động chấm bài thi trắc nghiệm với OpenCV
Ý tưởng
Dạo này mình rất có hứng thú với Xử lý ảnh ẻo các thứ các thứ và thật sự thì nó quá thú vị các bạn ạ. Quay trở lại với đề tài của chúng ta nếu như chúng ta muốn xây dựng một hệ thống chấm bài thi trắc nghiệm thì hãy THAY ĐỔI CÁCH NHÌN của chúng ta về bài thi trắc nghiệm nhé, ý của mình là thay vì coi nó như một tờ giấy, thực hiện so sánh thủ công giữa tờ đáp án và tờ giấy thi thì chúng ta có thể coi chúng như hai bức ảnh thôi. Việc còn lại của chúng ta đó chính là so sánh hai bức ảnh đó và tìm ra có bao nhiêu điểm khác biệt giữa chúng. Tư tưởng chính là như vậy tuy nhiên để thực hiện được thì chúng ta cần chia nó thành một số bước nhỏ như sau: (***Chia để trị đó mà (^_^)***)
- Bước đầu tiên hay còn gọi là bước một:: Nhận dạng phần bài thi trong một bức ảnh, chúng ta cần phải biết phần nào trong bức ảnh là bài thi của chúng ta để mà xử lý chứ phải không nào. Việc này được thực hiện bằng các kĩ thuật xử lý ảnh mà mình sẽ trình bày rõ ràng trong các phần tiếp theo ngay trong bài viết này. Kết quả nó sẽ kiểu như sau

- Bước hai: Trong phần bài thi đã được nhận dạng ở bước 1, chúng ta cần nhận dạng các dòng của từng bài thi tương ứng với từng câu trả lời của bài thi

- Bước ba: Từ mỗi dòng của câu trả lời chúng ta cần phải nhận dạng được đâu là câu trả lời của thí sinh. Hay nói một cách dễ hiểu hơn là đâu là câu trả lời được tô đậm
- ***Bước bốn:***: So sánh câu trả lời của thí sinh với câu trả lời tương ứng trong đáp án chính thức
- Bước năm: Lặp lại các bước trên cho từng câu trả lời
- Bước sáu: Tổng hợp và đưa ra kết quả cho bài thi
Chuẩn bị vũ khí
Như chúng ta đã bàn bạc ở trên, có cả thảy 6 bước để xử lý bài toán này,. Như vậy là Đường lối tác chiến đã được vạch rõ. Tuy nhiên để đi đến được kết quả chúng ta cần phải trang bị một hệ thống vũ khí tối tân rất cần cho mục đích xử lý ảnh của chúng ta. Gọi là vũ khí tối tân như thực sự nó lại khá phổ biến trong những bài toán xử lý ảnh thế này. Chúng ta cùng điểm mặt qua một số công cụ đó nhé:
OpenCV
Nói đến lĩnh vực Computer Vision chúng ta không thể không nói đến một công cụ mạnh mẽ đó chính là OpenCV. Công cụ này tích hợp khá nhiều giải thuật về Xử lý ảnh và Học máy cùng với các tính năng tăng tốc GPU trong việc phân tích hình ảnh thời gian thực. Tóm lại là nó gần như đã quá phổ biến đến mức cứ nói đến Xử lý ảnh là người ta nghĩ ngay đến OpenCV 
Lý thuyết về Optical Mark Recognition (OMR)
Chúng ta cùng nhau bàn luận một chút về lý thuyết thực hiện cho các phần trên trước khi đi vào thực hành. Có thể rất ít bạn thích đọc những phần lý thuyết này nhưng mình khuyên các bạn không nên bỏ quả nó nếu như muốn hiểu thực sự bản chất của vấn đề là như thế nào. Cũng phải thôi, chiêu thức võ công (chính là các công cụ đó) có đẹp mắt đến mấy nhưng không có khẩu quyết tâm pháp thì mãi mãi cũng không thể tiến xa hơn được phải không nào. Vậy nên chúng ta cần phải biết một chút về lý thuyết đã. Vậy Optical Mark Recognition (OMR) nó là cái gì? Chúng ta có thể tạm dịch ra tiếng việt đó chính là Nhận dạng vùng được đánh dấu, điều này dựa trên một nguyên tắc đó là phản xạ quang học khiến cho những vùng nào có đánh dấu (ví dụ như ô được tô trong phiếu trả lời trắc nghiệm chẳng hạn) sẽ có khả năng phản xạ ảnh sáng yếu hơn các vùng còn lại. Đó là xét trên khía cạnh phần cứng thôi. Các thiết bị phần cứng này có một nhước điểm là với các thiết bị này, yêu cầu về việc đánh dấu, tạo mẫu, cũng như yêu cầu về chất liệu giấy in rất khắt khe. Ngược với các thiết bị đánh dấu truyền thống, các phần mềm nhận dạng đánh dấu (Optical Mark Recognition - OMR) cho phép người dùng tự tạo các mẫu và in chúng trên các chất liệu giấy thông thường. Phần mềm sẽ xử lý ảnh quét của mẫu sau khi điền mà không cần chất lượng ảnh quá tốt. Ví dụ như bức ảnh sau mình sẽ sử dụng làm ví dụ cho bài viết này 
Thi triển võ công
OK sau một hồi mày mò nghiên cứu giải pháp chúng ta đã biết được tư tưởng chính của phương pháp này đó chính là OMR và chúng ta sẽ sử dụng OpenCV để thực hiện ý đồ đó. Tất nhiên là chúng ta sẽ phải có một mẫu chuẩn của giáy thi trắc nghiệm rồi đúng không nào. Việc này không phải lo lắng lắm bởi vì mỗi mẫu đề thi trắc nghiệm đều được quy định theo chuẩn của quốc gia để phục vụ cho những kì thi lớn như Thi tốt nghiệp THPT hay Thi đại học. . Sau khi có mẫu giấy thi việc đầu tiên của chúng ta đó là thực hiện việc nhận dạng phần trả lời câu hỏi trong mỗi đề thi nhưng trước tiên chúng ta cần import một số thư viện cần thiết của OpenCV dã các bạn ạ
Import thư viện cần thiết
# import library
from imutils.perspective import four_point_transform
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
Tiếp theo chúng ta cần khởi tạo một biến toàn cục để lưu trữ đường dẫn của file ảnh chứa đáp án của thí sinh
if __name__ == "__main__":
img_path = './images/test_01.png'
Hoặc nếu như chúng ta không muốn cấu hình cứng trong code thì chúng ta có thể truyền đường dẫn của ảnh vào trong lúc thực thi chương trình theo thư viện argparse của Python. Chúng ta có thể làm như sau:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
args = vars(ap.parse_args())
if __name__ == "__main__":
img_path = args["image"]
Bản thân mình tháy cách truyền thế này hay hơn vì không lẽ mỗi lần muốn chấm đề thi cho mỗi học sinh lại vào chỉnh code thì tù vãi chày (^_^)
Lưu trữ câu trả lời đúng
Trước tiên chúng ta cần khởi tạo một list lưu trữ các đáp án đúng của bài thi đã. Chúng ta có thể lưu chúng thành một list như sau:
ANSWER_KEY = {0: 1, 1: 4, 2: 0, 3: 3, 4: 1}
giống như cái tên của nó chúng ta có thể hình dung biến ANSWER_KEY lưu trữ các đáp án đúng của câu trả lời theo dạng key => value với key = 0 tương ứng với câu trả lời đầu tiên. value = 0 tương ứng với đáp án A. Chính vì thế đáp án chính xác của bài thi tương ứng với ANSWER_KEY mô tả phía trên như sau:
- Question #1: B
- Question #2: E
- Question #3: A
- Question #4: D
- Question #5: B
Tiền xử lý ảnh với OpenCV
Bước đầu tiên trước khi thực hiện bất kì một bài toán về Machine Learning nào chúng ta cũng cần phải có một bước gọi là Tiền xử lý dữ liệu và trong trường hợp này cũng không ngoại lệ. Chúng ta cần phải Tiền xử lý ảnh đầu vào giúp chuyển chúng về những định dạng mà dễ dàng xử lý hơn cho máy tính. Bước đầu tiên trong xử lý ảnh này đó chính là chuyển về Grayscale (ảnh xám) bởi vì ảnh xám là định dạng thích hợp để xử lý ảnh. Ngay cả trong trường hợp yêu cầu nhiều màu sắc, một hình ảnh màu RGB có thể bị phân tách và xử lý thành ba hình ảnh grayscale riêng biệt. Hình ảnh Indexed cũng được chuyển đổi sang màu xám hoặc RGB cho hầu hết các thao tác. Chúng ta có thể tham khảo về định dạng này ở đây. Để thực hiện điều này với Python thì vô cung đơn giản, thư viện OpenCV đã trợ giúp chúng ta làm điều đó rất dễ dàng như sau:
# Convert to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Bước tiếp theo đó là giảm độ nhiễu của ảnh với Gaussian blur để đơn giản chúng ta có thể hiểu đây chính là bước khiến cho ảnh dễ dàng xử lý hơn với máy tính khi loại bỏ đi những góc cạnh và những vùng ảnh ít có ý nghĩa đối với việc xử lý từ đó khiến cho những vùng chính được nổi bật hơn. Định nghĩa cụ thể của nó như sau
Gaussian Blur là cách làm mờ một ảnh bằng hàm Gaussian. Phương pháp này được ứng dụng một cách rộng rãi và hiệu quả trong các phần mềm xử lý đồ họa. Nó cũng là công cụ phổ biến để thực hiện quá trình tiền xử lý (preprocessing) hình ảnh dùng làm dữ liệu đầu vào tốt cho các phân tích cao cấp hơn như trong Computer Vision, hoặc cho các giải thuật được thực hiện trong một tỉ lệ khác của hình được cho. Nó có thể giúp làm giảm nhiễu (Noise) và mức độ chi tiết (không mong muốn) của hình ảnh.
Bước này cũng được thực hiện bằng OpenCV một cách rất đơn giản như sau:
# Blur image using Gaussian blur
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
Nhận dạng khung bài kiểm tra
Việc nhận dạng ra khung bài kiểm tra vô cùng quan trọng trong bài toán này, lẽ dĩ nhiên bởi vì nếu không có khung bài kiểm tra thì chúng ta sẽ lấy cái gì mà chấm điểm bây giờ ??? Trong bài viết này không đi quá sâu về phương pháp tách khung của một bức ảnh tuy nhiên nếu các bạn muốn có thêm hiểu biết về nó thì chúng ta có thể tham khảo bài viết sau. Còn ở mức độ ứng dụng thì OpenCV đã thực hiện điều này cho chúng ta một cách dễ dàng
# Canny edge detector
edged = cv2.Canny(blurred, 75, 200)
Và đây là kết quả khi áp dụng phân tách khung bài kiểm tra

Lưu ý cách các cạnh của khung bài kiểm tra được xác định rõ ràng, với tất cả bốn đỉnh của bài kiểm tra được hiện diện trong hình ảnh. Vì vậy nên nếu bài kiểm tra bị rách thì nó sẽ không thể phân biệt được đâu các bạn ạ. Việc lấy khung của bài thi là một việc làm rất quan trọng. Chúng ta cần phải thực hiện điều đó trước khi tiến hành bước xử lý tiếp theo đó chính là nhận dạng từng dòng của đáp án trong bài kiểm tra, và bước cuối cùng đó chính là nhận dạng vị trí của đáp án trong bài kiểm tra đó.
Các nguồn có thể tham khảo về các hàm được sử dụng:
- findCountours: https://docs.opencv.org/ref/master/d9/d8b/tutorial_py_contours_hierarchy.html
- Các hàm điều chỉnh hình thái ảnh: https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
- numpypad: https://docs.scipy.org/doc/numpy-1.12.0/reference/generated/numpy.pad.html
- threshold: https://docs.opencv.org/3.4.0/d7/d4d/tutorial_py_thresholding.html
(@pham.van.toan - viblo)
Có thể bạn quan tâm:
Hướng dẫn lập trình nhận dạng hình ảnh với Opencv
Chạy tự động video Facebook và Youtube khi gắn vào website, blog ...
Tự động Kiểm tra thông tin người gọi đến | Call Look
Hệ thống order chuyên nghiệp cho quán ăn, cafe, nhà hàng...
Series Phản Phác Qui Chân – Học thuật toán để làm việc gì?
Giới thiệu đơn giản phân tích độ phức tạp thuật toán
Điều hành hãng xe công nghệ, ứng dụng đặt xe trên smartphone ...
Hướng dẫn xác định chi phí, giá phần mềm, giá website, giá ứng dụng
ứng dụng công nghệ vào giáo dục
giáo dục thông minh, công nghệ giáo dục, Mobile application for ...
Tư vấn và xây dựng game giáo dục, tương tác thực tế ảo (AR, VR ...
DVMS chuyên:
* Viết ứng dụng cho smartphone và máy tính bảng: iPhone, iPad , Android, Tablet, Windows Phone, Blackberry, Uber app, Grab app, mạng xã hội, vận tải thông minh, thực tế ảo, game mobile,...
* Viết ứng dụng tìm và đặt xe, các hệ thống theo mô hình kinh tế chia sẻ, uber for x, ứng dụng giúp việc,...
* Xây dựng các giải pháp quản lý vận tải, quản lý xe công vụ, quản lý xe doanh nghiệp, phần mềm và ứng dụng logistics, kho vận, vé xe điện tử,...
* Tư vấn và xây dựng mạng xã hội, tư vấn giải pháp CNTT cho doanh nghiệp, startup, ...
Quý khách xem Hồ sơ năng lực của DVMS tại đây >>
Quý khách gửi yêu cầu tư vấn và báo giá tại đây >>








